
Evaluation of answers - Danger: Reference answer
The danger of reference answers
When you are quick with the foundation of your evaluation-system, you can easily trick yourself.

How evaluation-systems usually assess answers
In LLM evaluation systems, comparing two answers is often done by measuring the vector similarity between a reference answer and the answer under test.
Consider the following scenario: The question is: "Is Vienna the capital of Austria?" The reference answer is: "Yes"
Now, let's evaluate two possible answers:
- Answer 1: "Yes"
- Answer 2: "Yes, Vienna is the capital of Austria"
The human perspective
From a human perspective, both answers are correct. Answer 2 might even seem more natural, as humans often elaborate or include parts of the question in their answer to confirm understanding.
The evaluation-system perspective
However, many AI evaluation systems rely on metrics that compare the answer under test directly to the reference answer, often using methods like vector similarity. Such systems would likely penalize Answer 2, or score it lower than Answer 1, despite its factual correctness.
The crucial point here is that while the metrics might indicate a discrepancy, both answers are, in fact, correct in the given context. If we solely rely on these common metrics, Answer 2 would receive a lower score.
Suggested approach
A suggested approach to mitigate this is to incorporate both the reference answer and the original question into the evaluation process. This way, the system can better understand that simple, correct restatements or elaborations based on the question's content should not lead to a penalty.
Also advancing the evaluation-system to use a judge LLM to evaluate the answers can help a lot. But make sure to test the judge because it might as well lead to 'unfair' and therefore distorted results.
Architecture of the evaluation-system
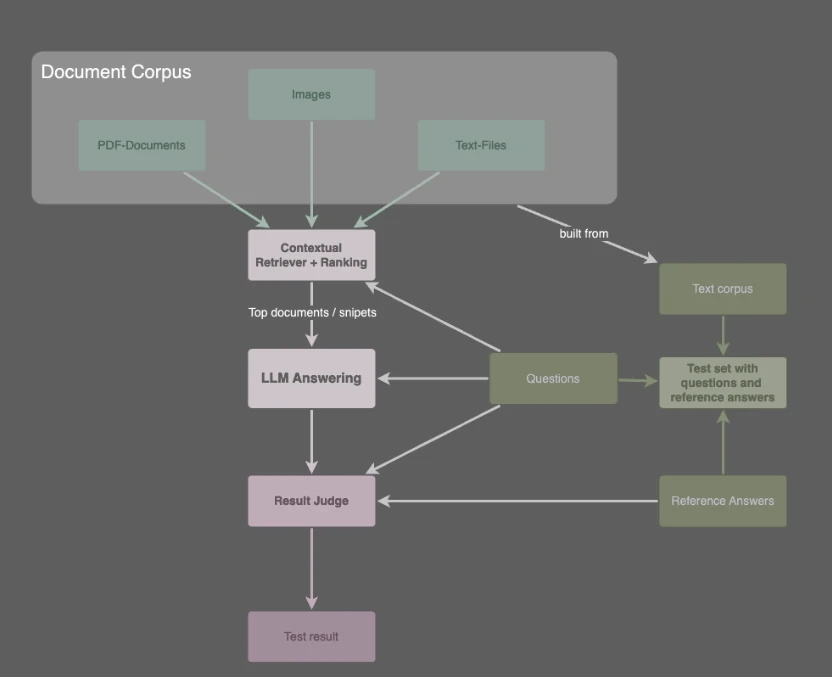
System Workflow
The process begins with the Document Corpus, from which the Contextual Retriever + Ranking component extracts the most relevant information (top documents/snippets) for a given Question. This retrieved context, along with the original Question, is then passed to the LLM Answering component, which generates an answer.
For evaluation purposes, a Test set with questions and reference answers (derived from a separate Text corpus and Reference Answers) is used. The Result Judge takes the LLM's answer, the original Question from the test set, and the corresponding Reference Answer to evaluate the LLM's performance, ultimately producing a Test result.
The image depicts a common architecture for an LLM-based evaluation system. Here are the key components and their roles:
Key Components
- Document Corpus: This is the collection of source documents that the system uses as its knowledge base. It can include various file types like PDF-Documents, Images, and Text-Files.
- Contextual Retriever + Ranking: This component processes the Document Corpus to find and rank the most relevant documents or snippets of text in response to a query or question.
- LLM Answering: This is the Large Language Model responsible for generating a human-like answer. It uses the context provided by the retriever and the input question.
- Questions: These are the prompts or queries fed into the system, both for generating answers and for testing the system's performance.
- Test Data: This group includes:
- Text Corpus: A separate collection of texts used specifically for creating evaluation data.
- Reference Answers: Pre-defined, ideal answers to the test questions.
- Test set with questions and reference answers: A curated dataset built from the Text Corpus and Reference Answers, used to systematically evaluate the LLM's responses.
- Result Judge: This component assesses the quality of the LLM's generated answer. It compares the LLM's output against the corresponding Reference Answer and the original Question.
- Test Result: The final output of the evaluation process, indicating the performance of the LLM Answering component based on the Result Judge's assessment.
Analysis outcomes you can gather with such a system
Click on the image below to download the Chat with your docs-presentation as PDF.
