
Preface
This article is a collection of existing research on the topic of AI reasoning that I came across over the last year. I wanted to share it with you, because I think it's a fascinating topic and I think it's important to understand the limitations of AI reasoning. This blog post is not meant to go deep into the topic, but rather to give you a high-level overview of the current state of research.
All credits go to the original authors of the research papers and the videos.
The AI Reasoning Riddle: Are LLMs Truly Thinking or Just Pattern Matching?
The danger of simplistic assumptions about LLM capabilities.
Recent advances in Large Language Models (LLMs) have demonstrated impressive performance in complex tasks, especially in mathematics and coding. Benchmarks like GSM8K suggest strong performance on grade-school math problems. However, a critical question remains: are LLMs genuinely reasoning, or are they sophisticated pattern-matching machines?
What started as isolated concerns has evolved into a comprehensive body of research revealing systematic limitations. From 2024 through 2025, researchers have been documenting consistent patterns that reveal limitations in AI reasoning across state-of-the-art models.
Let's trace through what this mounting evidence is telling us:
The Timeline of Research: Key Findings
Fall 2024: Research Findings October 2024 brought the landmark GSM-Symbolic study, which systematically demonstrated how LLMs show noticeable variance when questions are slightly altered—even minor changes to numerical values can cause significant performance drops, while they remain oddly robust to superficial changes like proper names.
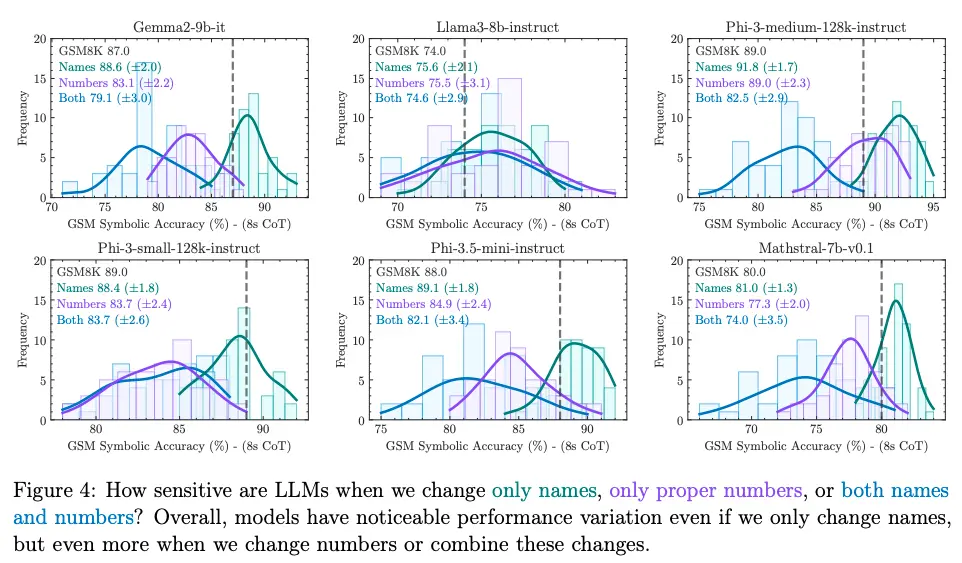
December 2024 research confirmed that LLMs don't genuinely reason step-by-step in many cases, laying groundwork for understanding their limitations.
2025: Comprehensive Studies Recent 2025 studies have provided the most comprehensive view yet:
- February studies on perturbation testing revealed the "irrelevant information catastrophe"—adding seemingly relevant but ultimately irrelevant information can cause performance to plummet by up to 65%
- March 2025's "Numberland" study exposed their fragile number sense in trial-and-error tasks
- April 2025 research revealed the "think-to-talk" vs. "talk-to-think" phenomenon, showing that for simple problems, LLMs often determine answers before generating their explanations, essentially creating post-hoc justifications
- June 2025 brought Apple's comprehensive "Illusion of Thinking" research, revealing the complexity sweet spot paradox in reasoning models
The Core Limitations Revealed
| Limitation | Description | Impact |
|---|---|---|
| Fragile "Reasoning" | LLMs show noticeable variance when questions are slightly altered. Even minor changes to numerical values can lead to significant performance drops, while being more robust to superficial changes like proper names. | Unreliable performance on variations of the same logical problem |
| Irrelevant Information Catastrophe | Adding "seemingly relevant but ultimately irrelevant information" can cause performance to plummet by up to 65% across state-of-the-art models. LLMs blindly convert extra clauses into operations even when they carry "no operational significance". | Up to 65% performance drop from irrelevant context |
| The Memorisation Trap | LLMs memorise problem-solving techniques from training data and blindly apply them without assessing suitability for modified contexts. This goes beyond verbatim memorisation to inappropriate technique application. | Poor generalization to novel problem variations |
| Order Matters (Even When It Shouldn't!) | Unlike humans, LLMs are surprisingly sensitive to the order of premises or information presented, even if the logical structure remains the same. | Performance drops of up to 40% from reordering input |
| "Think-to-Talk" vs. "Talk-to-Think" | For simple subproblems, LLMs often determine answers before generating their Chain-of-Thought explanation, creating post-hoc justifications ("think-to-talk"). Complex calculations may be performed during CoT generation ("talk-to-think"). | Inconsistent reasoning transparency across problem types |
| The Overthinking Problem | Especially in distilled models, LLMs exhibit "overthinking," getting stuck in "excessive self-reflection" (repeating "wait," "let me check") without improving accuracy. | Increased computational cost with no accuracy benefit |
| Consistency Errors and Unfaithful Explanations | LLMs can generate correct answers from incorrect reasoning steps, or vice-versa, highlighting "spurious correlations" between internal reasoning and final answers. | Explanations may not faithfully represent actual reasoning process |
| Fragile Number Sense | When faced with trial-and-error search tasks like the "24 game," LLMs struggle significantly, indicating poor number sense and lack of human-like hierarchical reasoning. | Sharp performance drops on mathematical puzzle tasks |
So, why does this matter for your strategic recommendations?
- Reliability is Paramount: The fragility of LLM reasoning means they are not always robust to minor input variations, making their use in critical applications risky without robust safeguards.
- Cost Implications: "Overthinking" translates directly to higher token consumption and increased operational costs for commercial models.
- Misleading Metrics: Current benchmarks like GSM8K might provide an "optimistic bias" due to potential data contamination, meaning real-world performance could be worse.
- Strategic Deployment: Understanding these limitations is crucial for safe and efficient real-world applications. LLMs are powerful tools, but they are not yet genuine logical reasoners capable of nuanced understanding in all contexts.
Reasoning Models: Performance Patterns Across Complexity Levels
Recent research titled "The Illusion of Thinking" provides additional insights into reasoning models like OpenAI's o1/o3, DeepSeek-R1, and Claude 3.7 Sonnet Thinking. See also Reasoning LLM ($$$$) Overthink for a deep dive into the overthinking problem.
Key Findings:
The Complexity Sweet Spot Paradox: These "reasoning" models don't uniformly outperform standard LLMs. Instead, they follow a curious three-zone pattern:
- Simple tasks: Standard LLMs often beat reasoning models in both speed and accuracy
- Medium complexity: Reasoning models finally show their advantage
- High complexity: Both types completely collapse, regardless of how much computing power you throw at them
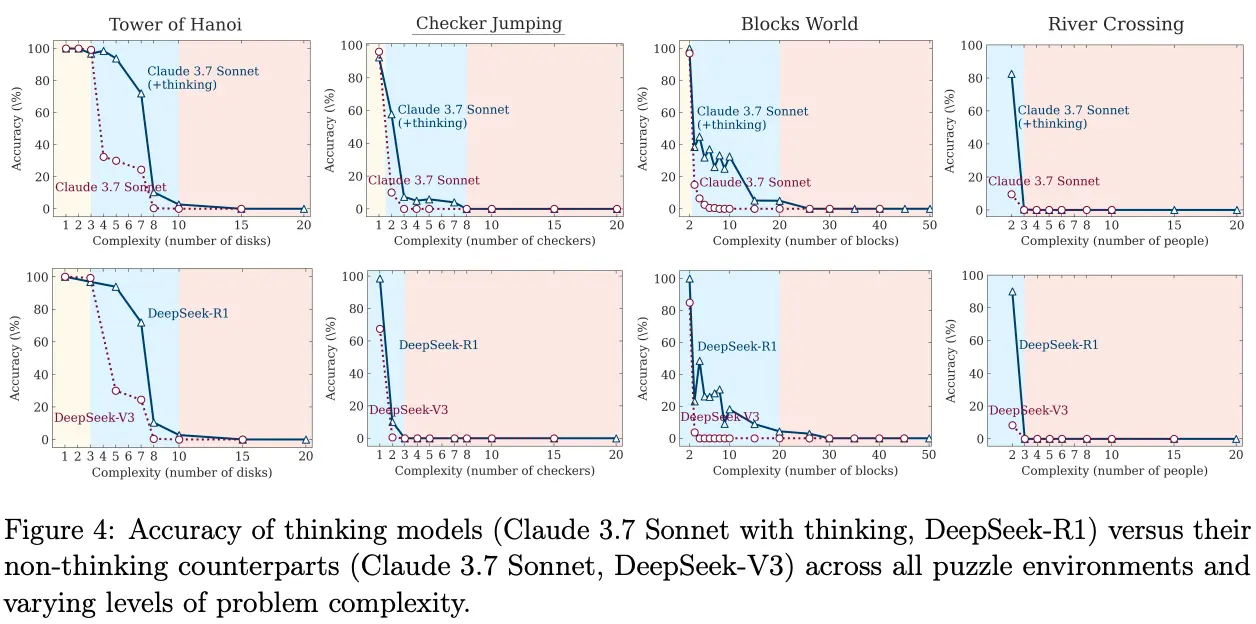
The "Giving Up" Phenomenon: Perhaps most intriguingly, reasoning models exhibit a counter-intuitive behavior where they initially increase their "thinking effort" as problems get harder, but then suddenly reduce their reasoning attempts when complexity crosses a critical threshold—even when they have unlimited token budget. It's as if the model says, "This is too hard, I'm not even going to try properly."
Algorithm Blindness: Even when researchers provided the exact solution algorithm in the prompt, reasoning models still failed at the same complexity points. This isn't about not knowing how to solve problems—it's about an inability to execute logical steps consistently, which strikes at the heart of what we consider "reasoning."
Benchmark Theater: The paper strongly criticizes relying on mathematical benchmarks like GSM8K, advocating instead for controllable puzzle environments that reveal the quality of reasoning, not just final answers. This suggests that many impressive benchmark scores might be masking fundamental reasoning deficiencies.
The Bottom Line: These findings reinforce that current "reasoning" models are still fundamentally sophisticated pattern matchers. They've gotten better at certain types of problems, but they haven't crossed the threshold into genuine logical reasoning—and they know when to stop trying.
Conclusion
The evidence is clear: while LLMs have achieved remarkable feats in language understanding and generation, their "reasoning" remains fundamentally different from human cognition. They are sophisticated pattern-matching systems that have learned to mimic reasoning processes, but they lack the robust logical foundations we might expect.
This doesn't diminish their utility—LLMs remain powerful tools for many applications. However, understanding these limitations is crucial for anyone deploying them in real-world scenarios.
The key is that although LLMs sometimes seem to reason and 'mimic' that reasoning in a very useful way, they are not yet able to reason in a way that is robust and reliable.
How this blog post was made
- NotebookLM helped a lot structuring and combining the sources
- Writing and layouting was done with Cursor (Claude Sonnet 4 Thinking)
- And I went through it, adapted, and was able to craft this with the help of AI
I had the final say in this post though 😉
Sources
| Title | Link | Date | Type |
|---|---|---|---|
| The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity | June 2025 | Research Paper | |
| Evaluation of answers - Danger: Reference answer (from my "AI-Challenges Blog") | LinkedIn post | May 22, 2025 | Blog Post |
| Think-to-Talk or Talk-to-Think? When LLMs Come Up with an Answer in Multi-Step Reasoning | arXiv | April 17, 2025 | Research Paper |
| Large Language Models in Numberland: A Quick Test of Their Numerical Reasoning Abilities | arXiv | March 31, 2025 | Research Paper |
| The AI Reasoning Paradox: Why Agents FAIL (from the awesome "Discovery AI") | YouTube | March 29, 2025 | Video Analysis |
| Reasoning LLM ($$$$) Overthink - Easy Solution (from the awesome "Discovery AI") | YouTube | March 27, 2025 | Video Tutorial |
| The AI Reasoning Lie (from the awesome "Discovery AI") | YouTube | March 3, 2025 | Video Analysis |
| MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations | arXiv | February 12, 2025 (v2) | Research Paper |
| How Likely Do LLMs with CoT Mimic Human Reasoning? | GitHub | 2025 - in progress | Research Code |
| Do LLMs Really Reason Step-by-Step? (Implicit Reasoning) | arXiv | December 27, 2024 (v3) | Research Paper |
| Calibrating Reasoning in Language Models with Internal Consistency | arXiv | December 5, 2024 | Research Paper |
| The new Apple paper about LLMs not truly reasoning actually prooves the opposite of their conclusion | Reddit Discussion | October 16, 2024 | Discussion |
| GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models | arXiv | October 7, 2024 | Research Paper |